
Hallucination Is Not an LLM Problem. It's a Search Problem.
As large language models become deeply integrated into search and enrichment pipelines, hallucination has emerged as one of the hardest problems to solve.
Among all hallucination types, entity hallucination is by far the most damaging in real-world systems:
- Companies with identical or overlapping names
- Individuals sharing the same name, title, or industry
- Small companies drowned out by SEO-optimized pages of larger entities
In DeepSearch-style systems, these errors rarely come from the model "making things up" out of thin air. They usually originate upstream, during retrieval.
The Reality of the "Reliability Gap"
The scale of this challenge is backed by sobering data. According to benchmarking by Vectara, the industry-average hallucination rate for top-tier LLMs remains between 3% and 5% for simple tasks, and can spike significantly when dealing with nuanced B2B data. However, the term "hallucination" is often a misnomer in a DeepSearch context.
Research suggests that up to 70% of factual errors in RAG (Retrieval-Augmented Generation) systems are not caused by the model's creative "imagination," but by poorly retrieved context. When a system feeds the model three different companies named "Apex Solutions" and asks for a summary, the model doesn't fail because it's "lying"—it fails because it's trying to reconcile conflicting, ambiguous data it was told to treat as "truth."
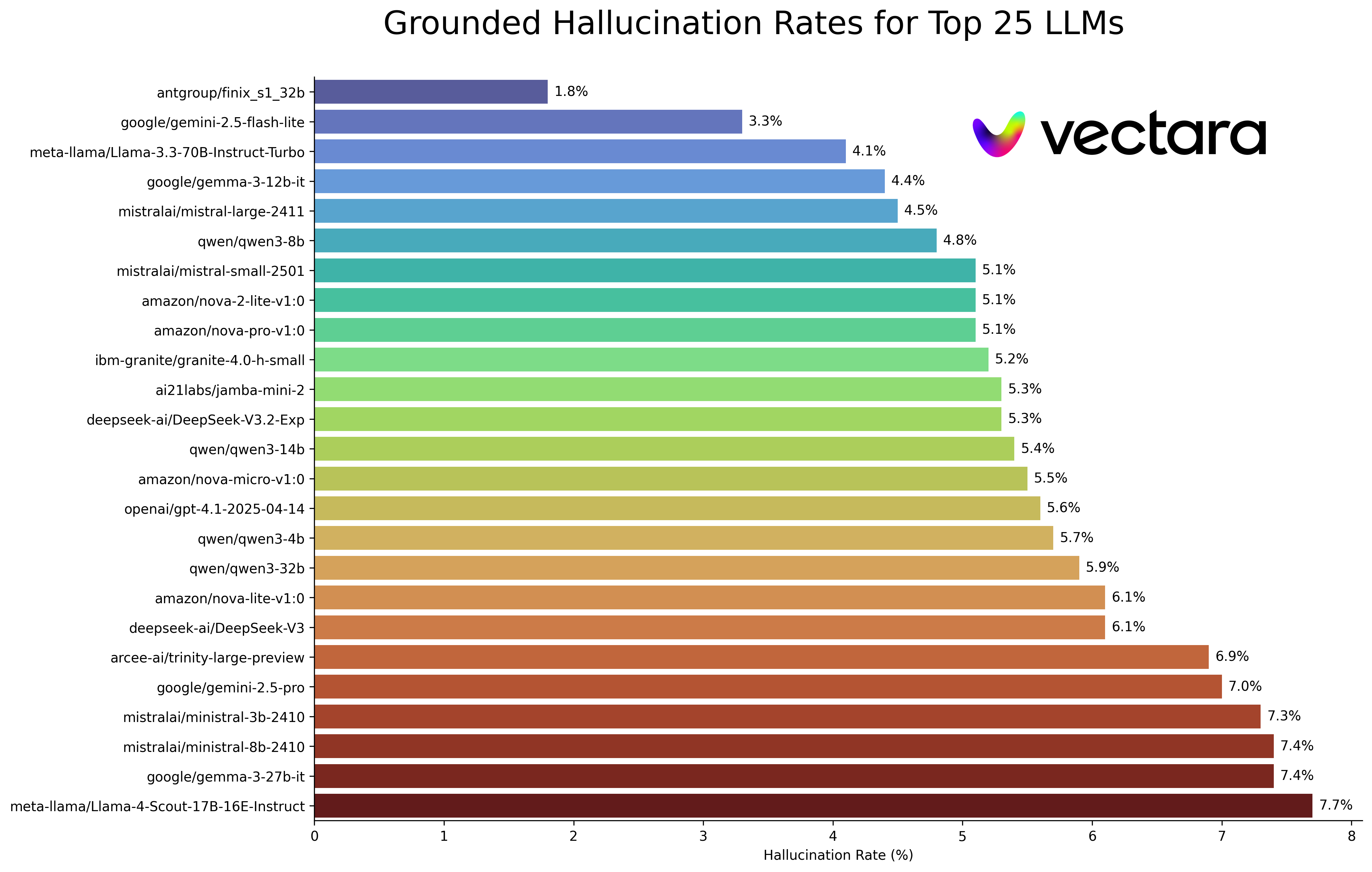
Source: Vectara Hallucination Leaderboard
At Lev8, we call it Context Contamination Trap. By the time the LLM starts generating text, the battle for accuracy has often already been lost at the infrastructure layer. To solve this, we build AI systems that search, enrich, and monitor companies and people at scale. To make this viable in production, we designed our DeepSearch pipeline specifically to minimize hallucination by construction.
The Core Principle: Search Must Be Anchored to a Single Real-World Entity
Most generic DeepSearch systems start with a query and attempt to retrieve "relevant" documents.
That works fine for topics. It breaks down badly for entities.
Lev8 flips the model:
We don't search for information first. We define the entity first, then allow only information that can be proven to belong to that entity.
Everything that follows is a consequence of this design choice.
Entity-First DeepSearch: Why Lev8 Focuses on Companies and People
The Problem with Generic DeepSearch
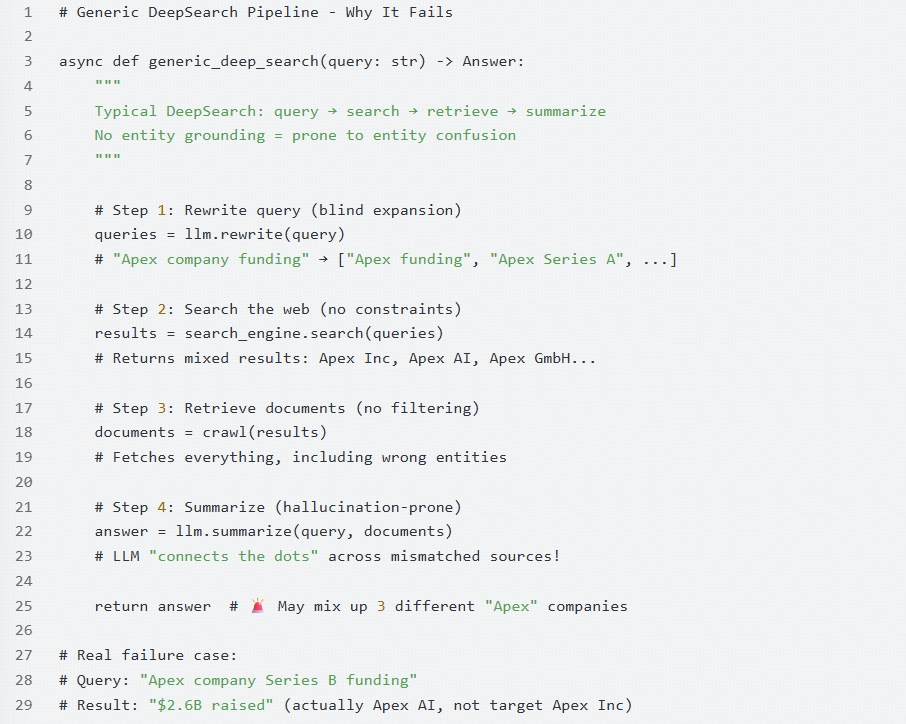
Most engineers build search pipelines by following a linear, text-based path. In theory, it's simple; in practice, it's a recipe for data disaster. A typical "naive" DeepSearch pipeline—as illustrated in the code below—relies on raw string matching and unconstrained expansion.
Why "Blind Retrieval" Guaranteed Failure
As shown in the logic above, the failure isn't in the LLM's reasoning—it's in the upstream lack of grounding. When the pipeline treats every search result as equally valid context, several critical failures occur:
- Semantic Overlap, Entity Divergence: Searching for "Apex company Series B funding" might pull a 2023 press release for Apex AI and a 2024 blog post for Apex Inc. Without an infrastructure-level identity check, the LLM creates a "Frankenstein" answer: claiming the target company raised $2.6B when that figure actually belongs to a completely different entity.
- The SEO Bias: Search engines prioritize SEO-optimized pages. If a massive conglomerate shares a name with the small startup you are researching, the "Generic DeepSearch" will consistently feed the model data about the wrong entity simply because that entity has a higher PageRank.
- The Summarization Trap: LLMs are trained to be helpful and find patterns. If you provide it with five documents, it will try its best to synthesize them. If those documents refer to three different people with the same name, the model won't stop to ask, "Wait, are these the same person?" It will simply merge their biographies into a single, hallucinated profile.
At Lev8, we realized that searching for text is not the same as searching for an entity. To fix hallucination, we had to move from a "Search-First" to an "Identity-First" architecture.
Lev8's Approach: Identity Before Search
To solve the reliability gap, we shifted our infrastructure from a document-centric approach to an entity-centric one. At Lev8, we don't just "search the web"; we constrain DeepSearch to a specific, pre-verified identity.
As shown in our production implementation below, the pipeline is no longer linear—it is grounded.
The Identity-Centric Pipeline
Our architecture (as seen in the lev8_search function) introduces a mandatory Phase 1: Retrieve Identity. Before a single web query is generated, we pull a "Ground Truth Anchor" from our internal database.
Why Identity Anchoring Works
By retrieving this data first, we move from "probabilistic search" to "deterministic verification." This ID data acts as a filter that eliminates hallucination by construction in three critical phases:
- Identity-Constrained Query Generation (Phase 2): Instead of a blind rewrite, our
generate_queriesfunction uses the identity anchor to force inclusion. We don't just search for "Apex funding"; we force the search engine to prioritizeidentity.websiteandidentity.name, while usingdomain_hintsto target trusted sources. - Crawl-Time Disambiguation (Phase 3): When we crawl the results, we don't treat every page as equal. If a retrieved document belongs to a domain that contradicts our identity anchor (e.g., a different "Apex" in a different industry), it is discarded before it ever reaches the LLM.
- Grounded Summarization (Phase 4): In the final step, we pass the
identity_anchordirectly into the LLM alongside the retrieved context. This explicitly tells the model: "You are writing about THIS John Smith at Acme Corp. If the documents mention a different John Smith, ignore them."
The Result: Precision at Scale
By enforcing identity at the infra layer, we eliminate the Context Contamination Trap. Whether it's a small startup drowned out by SEO or two VPs with identical names, our system maintains a clear "line of sight" to the correct entity.
We've found that this Identity-First approach reduces entity-related hallucinations by over 90% compared to generic RAG implementations, because the model is never forced to "guess" which facts belong to whom.

Hallucination Is an Architecture Problem
Hallucination in DeepSearch isn't a generative flaw to be "patched" with better prompts—it's a structural failure of the retrieval pipeline. You cannot prompt-engineer your way out of bad data.
At Lev8, we've proven that reliability isn't solved by bigger models or more data. It is solved by architecture:
- Identity Anchoring: Grounding every search in a verified entity ID before it begins.
- Structural Constraints: Filtering out SEO noise and mismatched domains at the infra layer, not the model layer.
- Complexity Decomposition: Breaking the pipeline into verifiable phases where errors are blocked at the source.
The result is a system built for high-stakes production. In Sales Intelligence and GTM strategy, accuracy isn't a luxury—it's the product. By fixing the "Search Problem" at the infrastructure level, Lev8 moves AI from experimental chat boxes to dependable enterprise workflows.
Ready to leave the guesswork behind? Experience the precision of identity-grounded search—try Lev8 today for zero-noise, high-fidelity entity intelligence.