
Anthropic recently released Claude Opus 4.7, positioning it as its flagship general-purpose model for complex reasoning and agentic coding. Official benchmarks point to stronger software engineering performance, higher-resolution vision, and more controllable compute settings. At the same time, early community feedback has been mixed, especially around stricter instruction following, migration friction, and real-world token consumption.
This review separates the launch-day upgrades from the practical tradeoffs: where Claude Opus 4.7 clearly improves, where teams may feel new pressure, and why workflow design matters more than simply switching to the newest model.
Core Upgrades of Claude Opus 4.7
Anthropic focused this iteration heavily on high-difficulty professional tasks. The capability improvements are most evident in the following two domains:
Advanced Software Engineering and Autonomous Verification
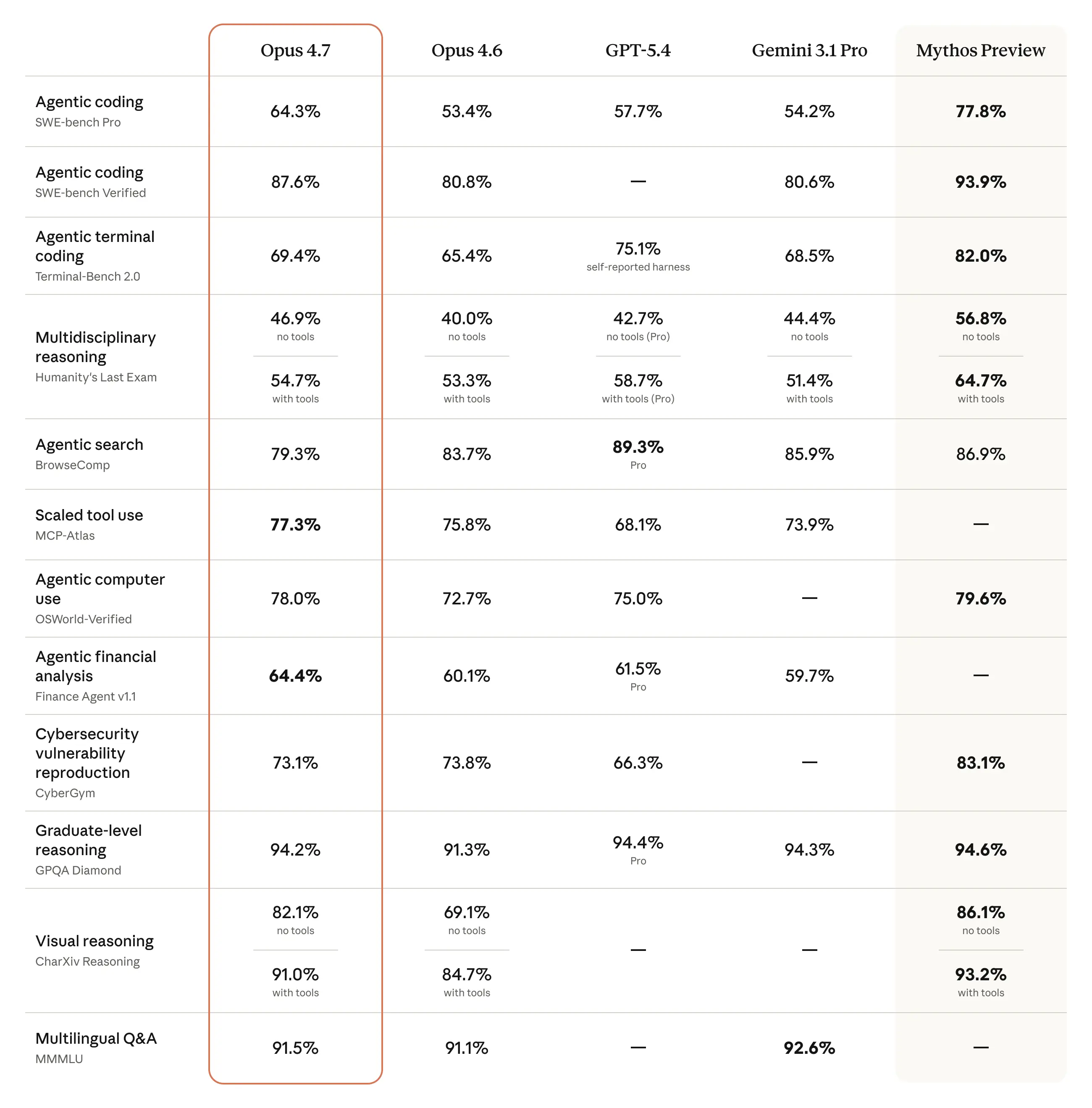
In the industry-standard SWE-bench Pro benchmark, Opus 4.7 scored 64.3%, representing an 11% leap over its predecessor, Opus 4.6. The improvement matters most in multi-file bug fixes, longer engineering tasks, and agentic workflows where the model has to plan, edit, validate, and recover from intermediate mistakes.
Anthropic also emphasizes stronger autonomous verification. In practical terms, Opus 4.7 is designed to check its own work more actively before returning a final answer, reducing the amount of manual review needed for routine coding and debugging tasks.
Tripled Visual Resolution for Multimodal Tasks
Vision capabilities also receive a major upgrade. Opus 4.7 now supports high-resolution image processing, extending the long-edge limit to 2,576 pixels, roughly 3.75 megapixels. That gives the model more room to inspect dense code screenshots, financial dashboards, technical diagrams, and UI states.
The tradeoff is cost. Higher visual fidelity can consume substantially more image tokens, so teams using screenshots or visual documents at scale need to manage resolution and routing carefully.
New API Features and Developer Controls
To support complex workflows, Anthropic introduced new parameter controls to help developers manage compute resources effectively.
The New xhigh Effort Level
Opus 4.7 introduces the xhigh effort level, sitting between the standard high and the more expensive max setting. Because max can consume significant resources during deep reasoning, xhigh gives developers a more practical middle ground for tasks that need serious reasoning without unlimited latency or cost.
Task Budgets in Public Beta
When executing multi-step autonomous tasks, large language models often risk draining token allocations before the task is complete. The new Task Budgets feature lets developers set a token ceiling for an entire agentic loop. Rather than acting like a hard stop, the budget gives the model a planning signal, helping it prioritize reasoning steps within a defined resource envelope.
Claude Opus 4.7 vs. Competitors: Where Does It Stand?
To evaluate Opus 4.7 in practical terms, we compared it against earlier Claude versions, Anthropic’s research previews, and OpenAI’s GPT-5.4.
For context, Anthropic’s unreleased Claude Mythos Preview appears to represent the upper ceiling of its current coding research line. According to Anthropic's Red Team reporting, Mythos Preview reached 77.8% on SWE-bench Pro, but it remains heavily restricted under Project Glasswing because of its dual-use cybersecurity capabilities. That makes Opus 4.7 the more relevant model for commercial teams today: powerful enough for serious coding workflows, but available in normal enterprise channels.
For everyday enterprise workflows, Opus 4.7 and GPT-5.4 remain the primary top-tier contenders.
The scores below are editorial ratings based on official release notes, public benchmarks, and early user feedback. They are not direct benchmark percentages.
| Evaluation Metric | Opus 4.7 | Opus 4.6 | Claude Mythos Preview | ChatGPT-5.4 |
|---|---|---|---|---|
| Coding / Agentic Execution | 5 | 4.4 | 5 | 4.6 |
| Knowledge / Document Processing | 4.7 | 4.5 | 4.2 | 4.8 |
| Logical Reasoning | 4.6 | 4.4 | 4.7 | 4.8 |
| Copywriting / Generation | 4.3 | 4.5 | 4.0* | 4.8 |
| Vision / Computer Use | 4.7 | 4.1 | 4.5 | 4.9 |
| Cost Efficiency | 3.8 | 4.2 | 1.5 | 4.6 |
(Note: Mythos scores are conservatively estimated for non-coding tasks based on limited public data.)
Opus 4.7 is arguably the top choice for heavy agentic coding workflows. Meanwhile, GPT-5.4 offers a more balanced experience for knowledge work, document formatting, and web retrieval.
The Controversies: Why Some Users Feel It "Got Worse"
Despite its professional strengths, Claude Opus 4.7 has drawn criticism from some early users around daily interaction quality, prompt migration, and hidden costs. These reports should be treated as community signals rather than controlled benchmarks, but they still matter for teams deciding whether to migrate production workflows.
The Limitation of Strict Instruction Following
Opus 4.7 follows literal instructions more strictly. Anthropic notes that the model is less likely to "fill in the blanks" for vague prompts at lower effort levels. That can be positive for deterministic workflows, but teams with older prompt libraries may see brittle behavior, rigid outputs, or unexpected refusals unless they tighten their instructions.
Retrieval Degradation and Over-Alignment
Some community stress tests report weaker accuracy during 1M-token retrieval tasks, including claims of large drops on specific needle-in-context evaluations. Other users describe higher refusal rates during routine code review or security-adjacent workflows. These reports are not yet a substitute for formal evaluation, but they highlight a real migration risk: Opus 4.7 may require more explicit retrieval instructions, clearer tool-use policies, and tighter acceptance tests than Opus 4.6.
Rising Costs from the New Tokenizer
While base pricing remains $5 per million input tokens and $25 per million output tokens, Anthropic notes that the new tokenizer can split the same text into roughly 1.0x to 1.35x more tokens depending on content. For production systems, that means nominal pricing is only part of the cost equation. Longer reasoning traces, higher effort settings, image-heavy workflows, and tokenizer changes can all increase the actual monthly bill.
What Opus 4.7 Really Means for Revenue Teams
Claude Opus 4.7 shows how fast frontier models leap forward—but the takeaway for enterprise GTM isn’t “upgrade at all costs.” Every model jump introduces hidden migration taxes: prompt re-tuning, evaluation drift, token inflation, tool-use quirks, and tighter budget controls.
For B2B lead generation, a smarter chat box alone won’t move pipeline. Real impact comes from embedding frontier-model power inside revenue agents—standardising prompts, orchestrating web intelligence, stitching buyer signals, and handing sales & marketing fully actionable outputs.
That is where platforms such as Lev8 become more important. As models grow both stronger and trickier, agent-native integration—not raw model chasing—will decide enterprise ROI
Agent > Raw Model — Four Lessons from Opus 4.7
| # | Opus 4.7 Challenge | Agent-Level Fix in Lev8 |
|---|---|---|
| 1. Token-cost inflation demands elastic budgets | The new tokenizer can inflate text up to 1.35 ×, and higher effort levels + images multiply the bill. | Each Lev8 agent enforces a Task Budget ceiling; low-value reasoning is auto-pruned so the run never blows cost caps. |
| 2. Prompt stability is the silent ROI killer | Strict instruction-following makes vague legacy prompts rigid or refused. | Lev8 wraps every call in a governed prompt layer—template library → runtime context injection → output validator/recovery—so downstream logic never depends on raw model quirks. |
| 3. Multimodal + long context only pay off when signals are stitched | Million-token windows & 2.5 K-px images are just pricey OCR if you feed one source at a time. | A Lev8 agent can ingest job posts, patent PDFs, SEC screenshots, and full DOMs in one pass, fusing firmographic + technographic + intent signals before emitting actions. |
| 4. Agentic loop ≫ single shot | Opus 4.7 adds autonomous verification and posts an +11 % SWE-bench jump, perfect for self-patching. | Lev8 agents run parse → write → validate → retry internally; humans just review diffs—turning ad-hoc ETL into lights-out pipelines. |